On-Robot Learning With Equivariant Models
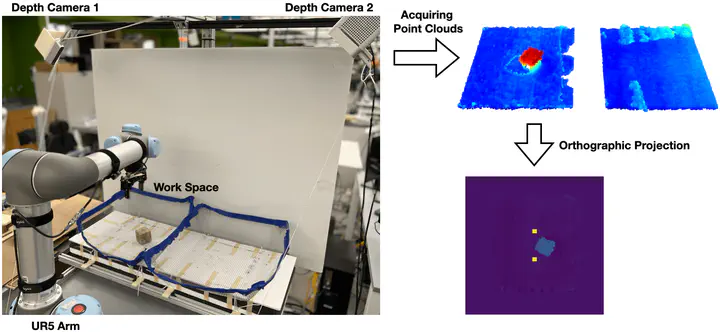 Image credit: Unsplash
Image credit: UnsplashAbstract
Recently, equivariant neural network models have been shown to im- prove sample efficiency for tasks in computer vision and reinforcement learning. This paper explores this idea in the context of on-robot policy learning in which a policy must be learned entirely on a physical robotic system without reference to a model, a simulator, or an offline dataset. We focus on applications of Equivariant SAC to robotic manipulation and explore a number of variations of the algorithm. Ultimately, we demonstrate the ability to learn several non-trivial manipulation tasks completely through on-robot experiences in less than an hour or two of wall clock time.
Type
Publication
In 2022 Conference on Robot Learning